- Đăng vào
Scraping và crawling Web với Scrapy
Giới thiệu
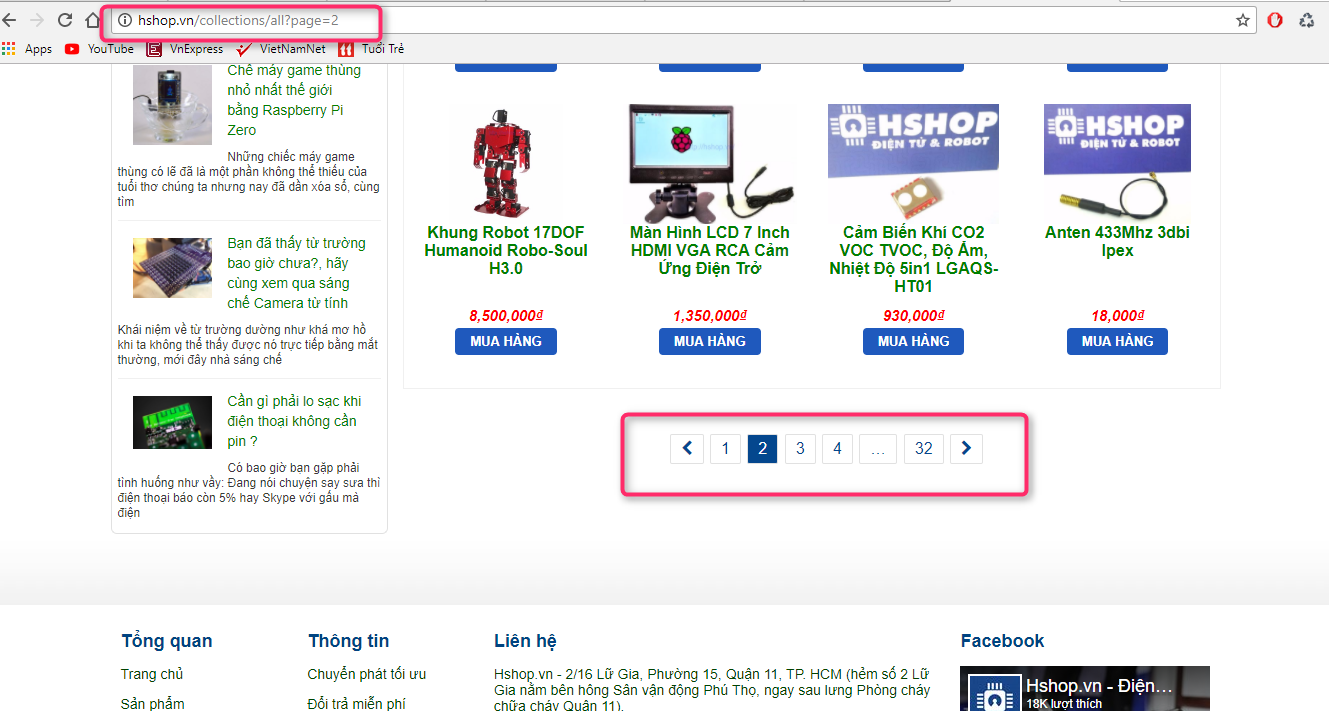
Trong bài viết này sẽ giới thiệu ví dụ đơn giản thu thập dữ liệu từ một trang web bằng cách sử dụng Scrapy. Cụ thể mình sẽ thu thập toàn bộ thông tin sản phẩm của một cửa hàng trên mạng, ví dụ: http://hshop.vn/collections/all?page=1

Tiến hành
- Cài Python 2.7
- Cài packages Scrapy
pip install Scrapy
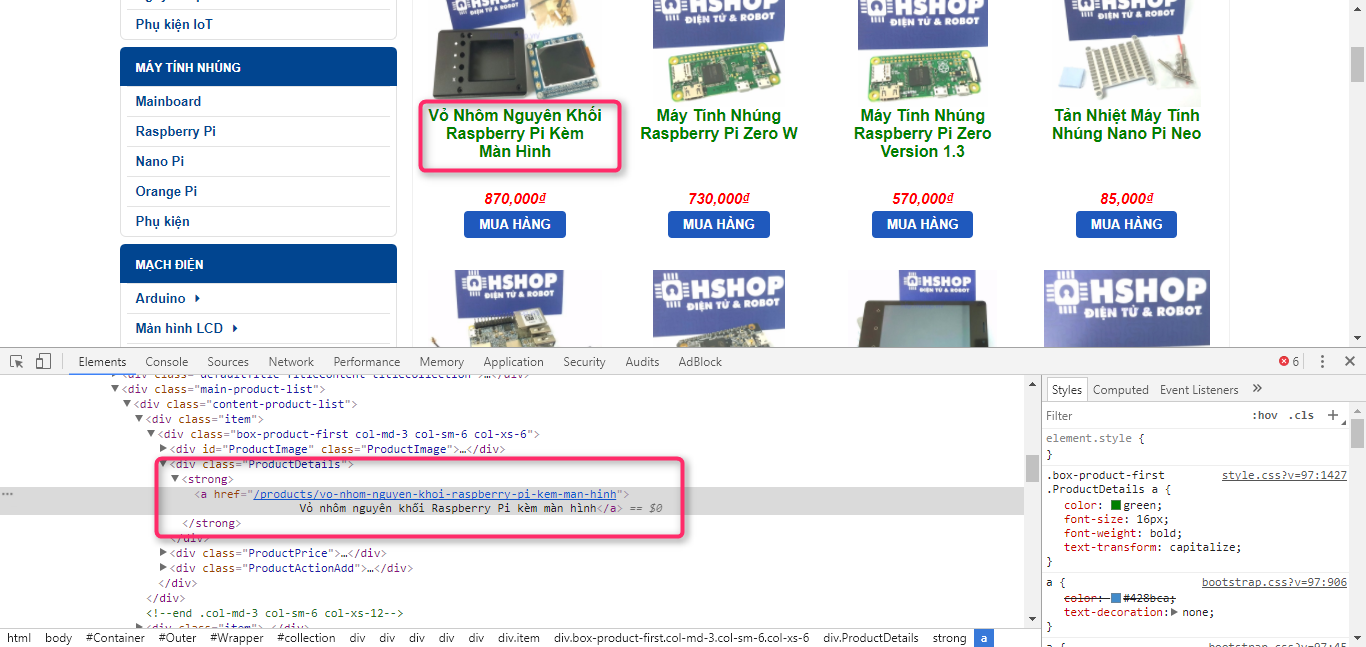
Chúng ta có thể thấy thông tin của mỗi sản phẩm được đặt trong thẻ div và class là ProductDetails
<div class="ProductDetails">
<strong
><a href="/products/khung-robot-17dof-humanoid-robo-soul-h30"
>Khung robot 17DOF Humanoid Robo-Soul H3.0</a
></strong
>
</div>
Để lấy tên của sản phẩm và đường dẫn tương đối của
products_name = response.xpath("//div[@class='ProductDetails']//a/text()").extract()
products_url = response.xpath("//div[@class='ProductDetails']//a//@href").extract()
Trang web này tất cả sản phẩm hiện thị trong 32 page, đoạn code dưới dây sẽ thu thập toạn bộ tên các sản phẩm, đường link của từng sản phẩm, từ đó chúng ta có thể vào từ link sản phẩm và thu thập các meta data, hình ảnh vào cơ sở dữ liệu hoặc đơn giản hơn Scrapy hỗ trợ xuất dữ liệu sang file csv, xml...
Code Python
'''
Created on Oct 17, 2017
@author: nvtienanh
'''
# -*- coding: utf-8 -*-
import scrapy
import urlparse
BMSID = 42
class get_products(scrapy.Spider):
name = 'get_products'
start_urls = ['http://hshop.vn/collections/all?page=1']
num_pages = 33
for page in range(2, num_pages):
start_urls.append('http://hshop.vn/collections/all?page=%d'%page)
def parse(self, response):
domain_name = 'http://hshop.vn'
global BMSID
BMSModel = []
#Extracting the content using css selectors
products_name = response.xpath("//div[@class='ProductDetails']//a/text()").extract()
products_url = response.xpath("//div[@class='ProductDetails']//a//@href").extract()
for i in range(len(products_url)):
# ... compute some result based on item ...
BMSID = BMSID + 1
BMSModel.append('BMS%04d'%BMSID)
url = urlparse.urljoin(domain_name,products_url[i])
products_url[i] = url
for item in zip(products_name,products_url,BMSModel):
#create a dictionary to store the scraped info
scraped_info = {
'product_name' : item[0],
'product_url' : item[1],
'product_model' : item[2],
}
#yield or give the scraped info to scrapy
yield scraped_info
Full project Scrapy: đang cập nhật